Learning Deep Structured Semantic Models for Web Search using Clickthrough Data
DSSM:深度语义模型,主要目的是计算query和document的相似度,该模型是通过将文本数据已经用户的点击历史记录映射到一个相同维度的语义空间,计算query和doc之间的cosine相似度来返回query的召回集合。DSSM是一个监督学习的过程,假定query和点击doc是相关的,通过监督 学习的方法学习模型参数,目标函数是最大化点击的似然函数,即点击文档概率的交叉熵。
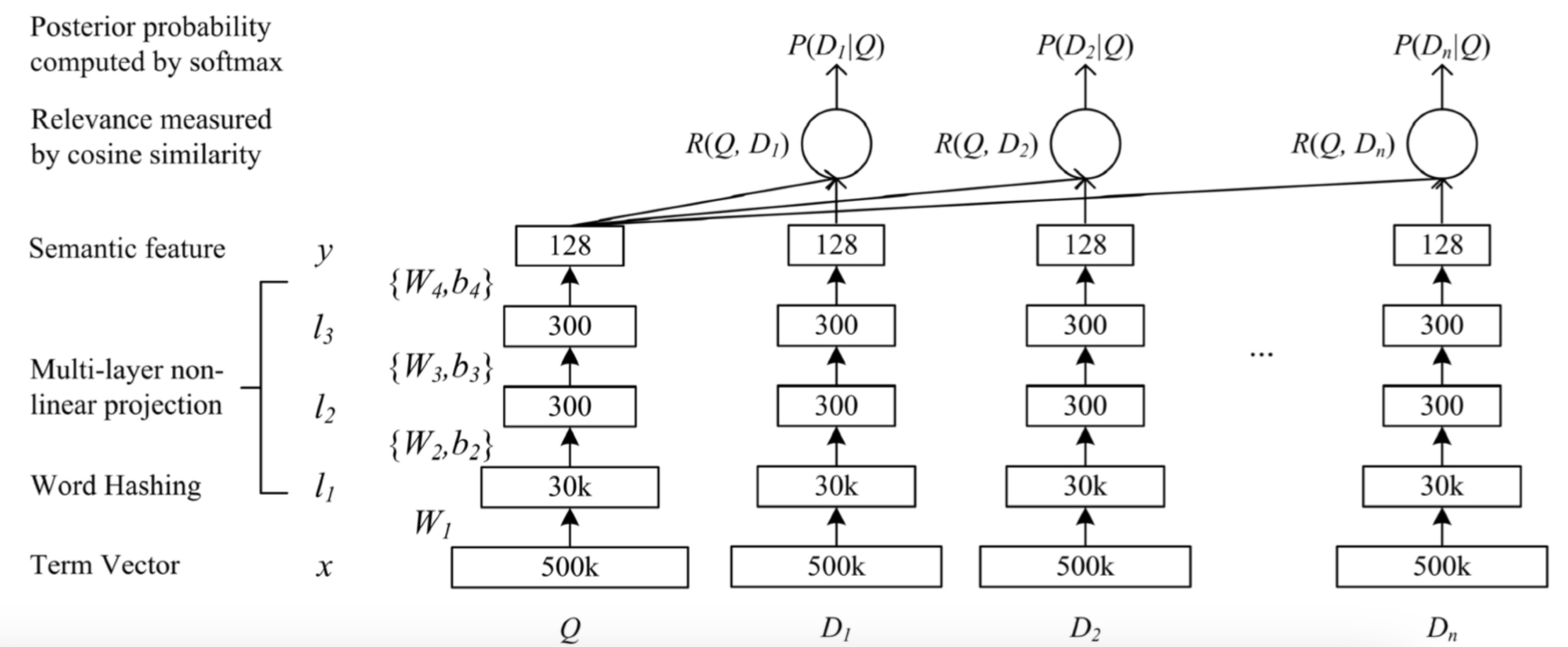
从这个图来看,DSSM将30k维度的输入经过3层DNN,将Query与Doc降低到相同的128空间,通过cosine测度度量5个doc(包含一个相关, 4个随机采样的不相关),最后统一通过softmax归一化。
论文中提出的 trick— word hashing 是针对英文预料的,该方法将一个word,前后家#,然后三个字母的切,这样两个不同的单词会产生相同的三元组,论文里面做了统计,500k个单词能够降维到30k,冲突概率仅有0.0044%。最后通过multi-hot编码的方式给对应位置上的元组置为1。这样做的好处是能够解决字典爆炸的问题,能够对unseen的单词特别鲁棒。
针对这个trick,对于中文文本如何处理呢?
对中文来说有效的操作是分词,常用的双字量级大约是百万级别,所以向量空间比较大,采用字的onehot比较合适,大概是1.5w左右。此处有人采用了偏旁和部首的方式处理。?
***该模型的优缺点分析:
优点:DSSM采用统一的有监督训练,不需要在中建过程做无监督模型的映射,因此精准度比较高。
缺点:采用的是词袋模型(Bow),因此丧失了语序信息和上下文信息。