所谓CTR预估,就是点击率转换的预估,即click through rate, 一般用在推荐广告系统中。简单来说,就是当用户预览网页或者在使用APP的时候,在用户浏览的页面中插入一些广告,如果用户在浏览的过程中点击了这些广告,就算做是一次成功的转化。因为考虑到了用户的因素,因此针对不同的人不同的爱好,系统会推荐不同的广告。如果是离线系统,一般采用AUC进行系统性能的评估,如果是在线系统,一般采用A&B Test的方式进行系统评估。
在推荐系统中,输入样本的特征包括了数值特征和类比特征,为了使得这些特征的形式保持一致,方便模型的训练,一般有两种可选方式:一是全部转换为数值特征,而是全部转换为类比特征,这对应着两种不同的解决方案即:[海量类别特征+简单模型] 和 [少量数值特征+复杂模型]。如果将全部特征转换为类别特征往往采用onehot的编码方案,对于原始的数值来说则需要进行离散化的处理,在这种情况下离散化后可以加强特征交叉。但是这种方案的缺点是会导致输入特征的稀疏性,同时还会出现在预测集中出现的特征组合从来没有再训练集中遇到过,这样就会使得模型对于这部分样本的准确率大大的下降。如果全部采用数值特征,对于原始的类别的列别特征就是使用embedding策略将其映射到一个低维度的实数向量空间中去,这个向量可以随机初始化也可以采用FM算法进行pre-training初始化。接下来通过多层神经网络结构和非线性的变换,提取高阶的特征交互信息。
总结在CTR模型,在近年来的文章的改变主要从以下几个方面:
- 串行和并行,AFM,NFM这些都是串行的网络,Deep&Wide, DeepFM是并行的网络
- 交叉项的特征提取,FM的二阶交叉,通过神经网络来获得(NFM),通过cross网络,借鉴残差网络(DCN)
- 计算方式,内积和外积。如xDeepFM是通过外积的方法,PNN里面分别介绍了外积和内积的计算的方法。
经典论文分享
Neural Factorization Machines for Sparse Predictive Analytics
Github地址:https://github.com/hexiangnan/neural_factorization_machine
NFM这篇文章的工作主要是在FM的基础上,在二次项部分做了创新。由于二次项捕捉的仅仅是二阶特征还不够高阶,所以通过一个神经网络来捕捉更加高阶的特征,这样的方法参数量少,但是效果很好。文章提出了一种Bi-Interaction operation 就是FM的二阶操作。
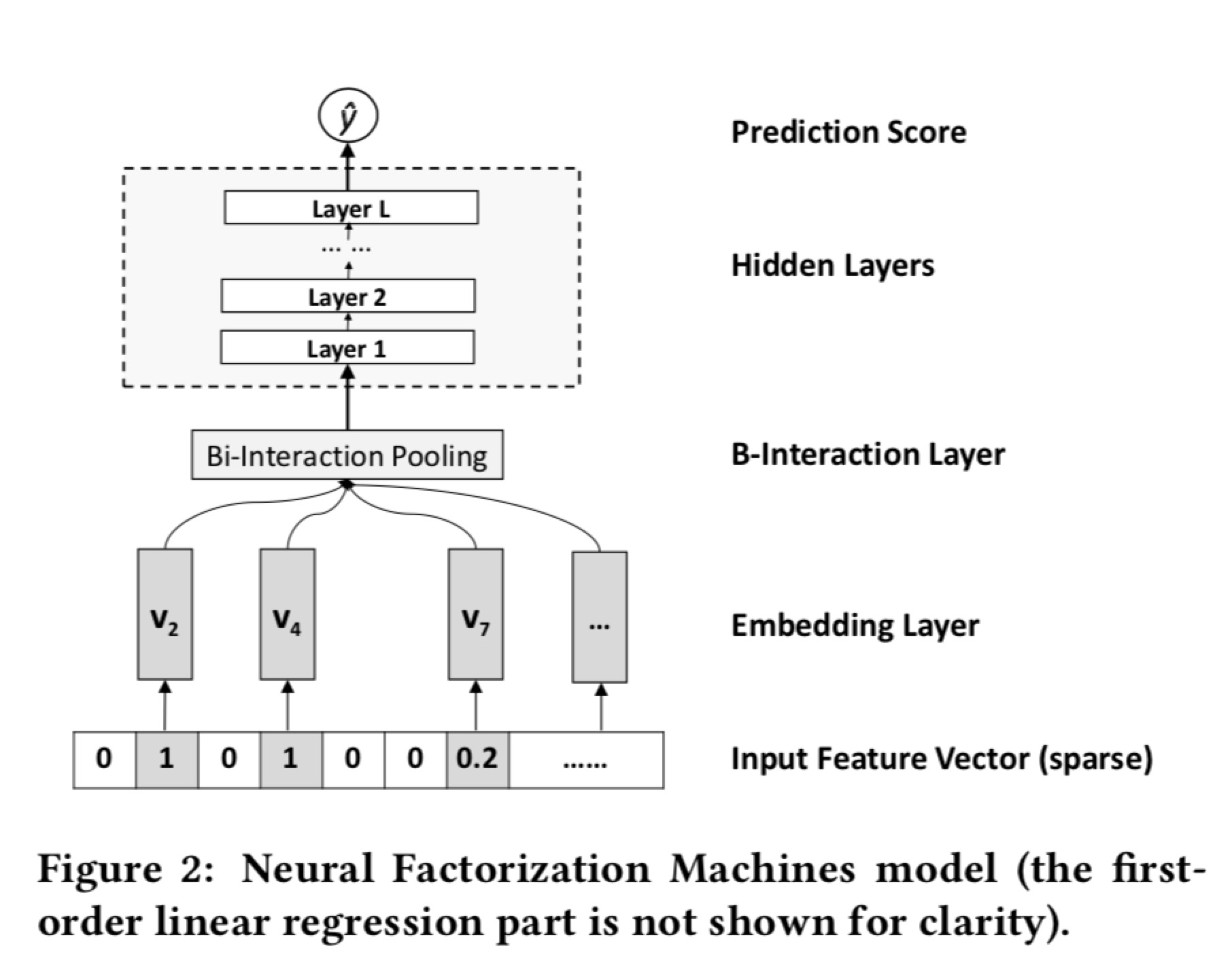
最后结果的表达式为:
即二次项作为神经网络的输入获得更高阶的输出。
可以看出,当BI层的神经网络为一层,且h向量全为1时,这个就是简单的FM模型。
Attentional Factorization Machines: Learning the Weight of Feature Interaction via Attention Networks
Github地址:https://github.com/hexiangnan/attentional_factorization_machine
AFM是一种将FM模型和Attention机制,并不是每一个二阶特征交叉的重要性都是一样的
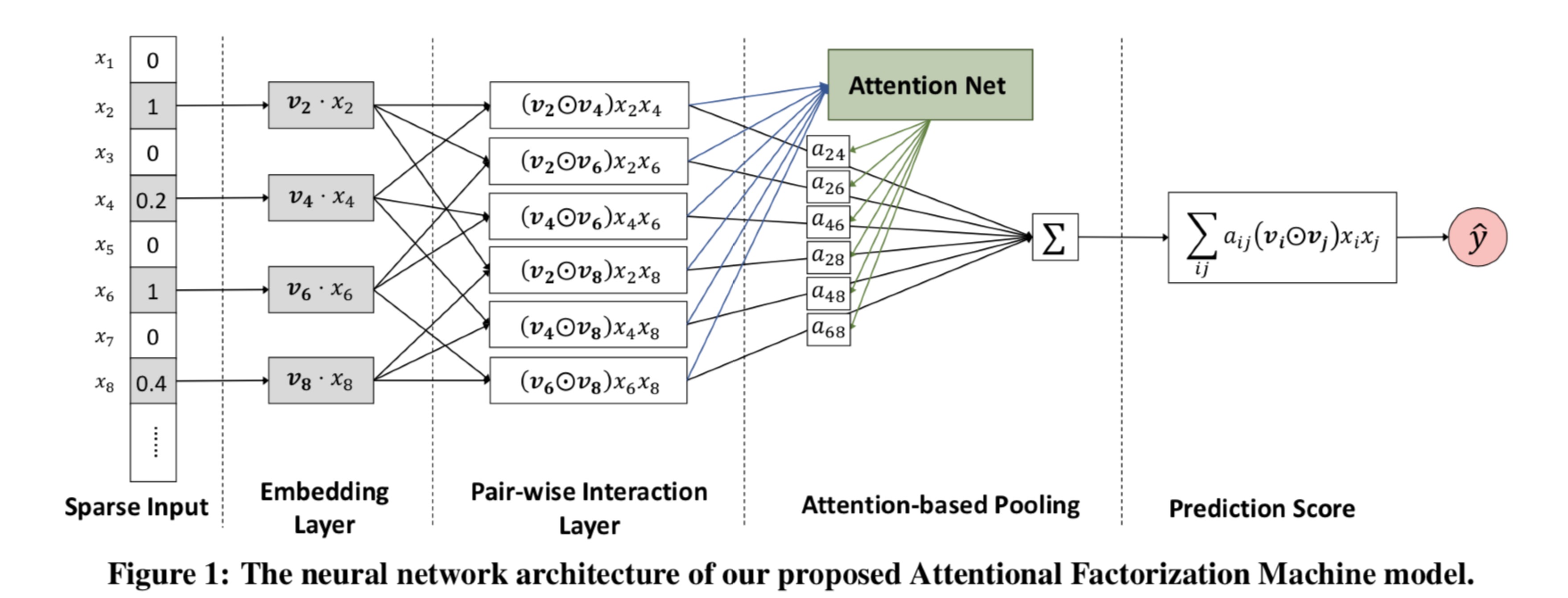
最后结果的表达式为:
Product-based Neural Network for User Response Prediction
Github地址:https://github.com/crazygirlfym/deep_learning/tree/master/ctr_models
PNN同样是在FM的基础上进行改进的。大部分的神经网络模型对向量之间的处理都是采用加法操作,而FM是通过向量的乘法来衡量两者之间的关系,这种“且”的关系能够更加严格的区分目标变量。采用乘法方式建模,可以通过向量做内积或者的操作。PNN首先对输入数据进行embedding处理,得到一个低纬度的vector,通过对这层任意的两个feature进行内积或者外积处理,最后把feature和相乘结果一起cancat,作为神经网络的输入层。

文章中定义了两种乘法,分别是IPNN(内积)和OPNN(外积),针对这两种方式也分别提出了优化方法:
IPNN : 原本计算方式是, 此时的维度是,计算代价为,借鉴FM的思想,考虑到为对称矩阵,可以将其分解为,则 , 时间复杂度为
OPNN:原本的计算方法是, 的计算的复杂度为, 计算代价太大,因此为了减少复杂度,论文中使用了叠加的思想重新定义了矩阵 ,计算的时间复杂度变为了
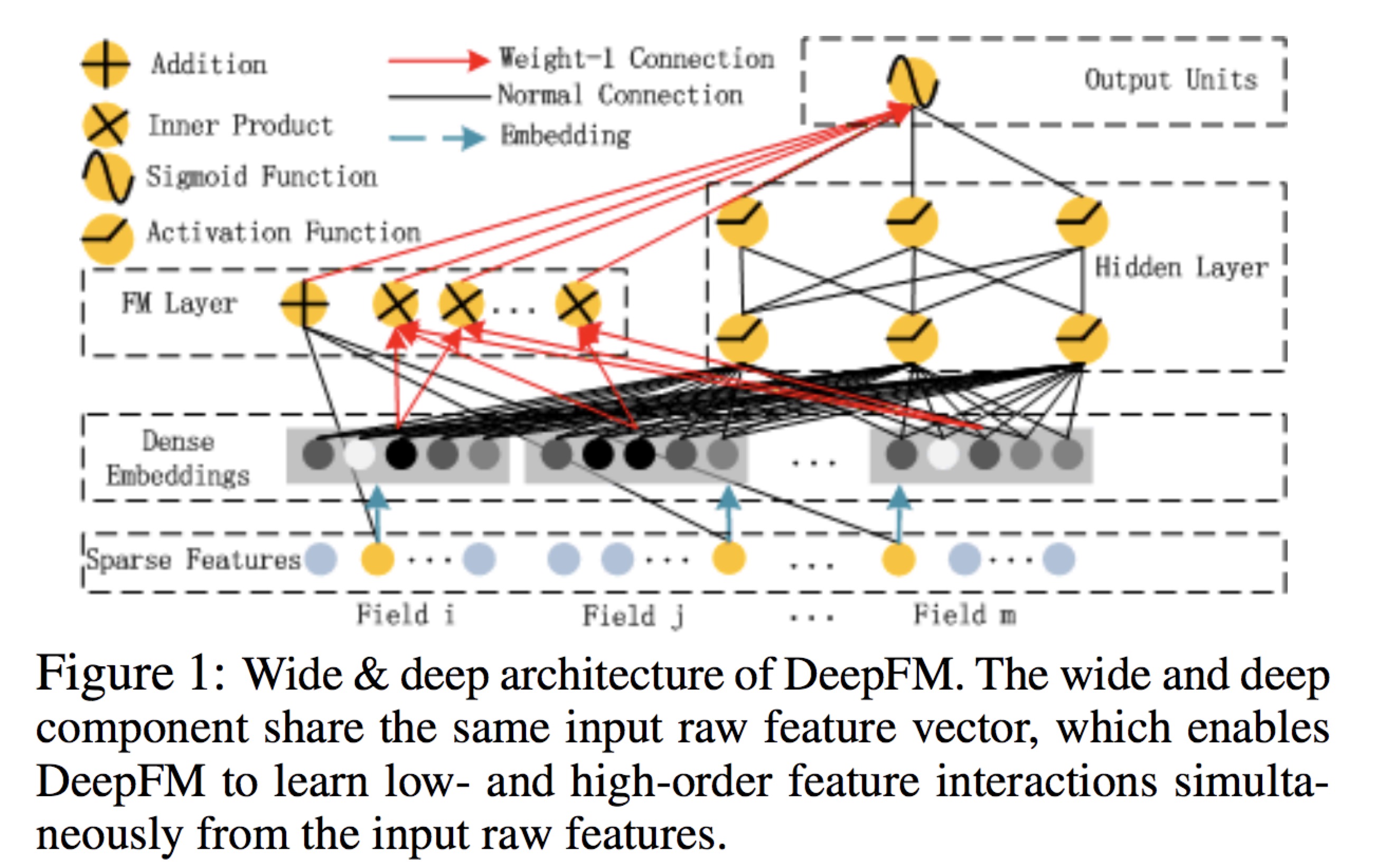
DeepFM:A Factorization-Machine based Neural Network for CTR Prediction
Github地址:https://github.com/ChenglongChen/tensorflow-DeepFM
deepFm这种结构是包括了“宽”和“深”两部分,可以使得从原生特征中同时学到低阶的特征之间的相互作用和高阶的特征之间的相互作用。相比于NFM这种模型是DNN和FM的串行结构,DeepFm是FM和DNN的并行结构,两部分共享相同的embedding层。
Deep & Cross Network for Ad Click Predictions
Github地址:https://github.com/crazygirlfym/deep_learning/tree/master/ctr_models/deepcross
Deep&Cross模型能够对sparse和dense的特征进行自动的特征学习,可以有效地不捕获有关于有限阶(文章中 提到的bounded degrees)上的特征交叉,学习到更为高级的非线性特征交叉,此过程无需人工特征,计算代价较低。DCN模型也是一个基于“宽度”的模型,并列连着一个cross network,一个deep network,最后将两个部分连接在一块。
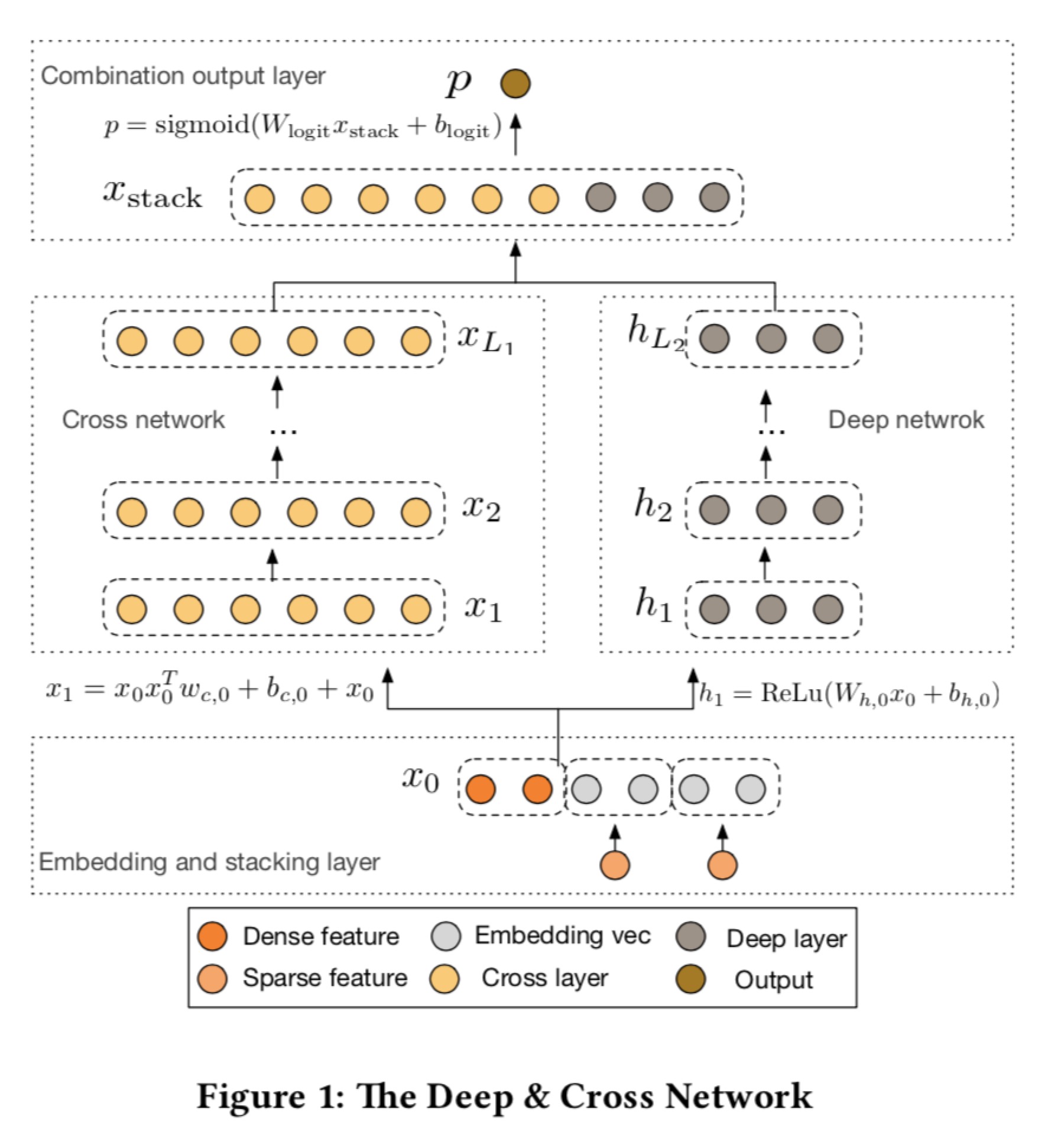 在cross网络中,通过显性特征的有效交叉,通过多个cross layers组成,计算方式是从公式可以看做,该部分借鉴了残差网络,将输入也加入其中,随着深度的增长,由此实现了特征的高阶交叉。在deep网络中就是一个多层的深度神经网络。
在cross网络中,通过显性特征的有效交叉,通过多个cross layers组成,计算方式是从公式可以看做,该部分借鉴了残差网络,将输入也加入其中,随着深度的增长,由此实现了特征的高阶交叉。在deep网络中就是一个多层的深度神经网络。
xDeepFM: Combining Explicit and Implicit Feature Interactions for Recommender Systems
Github地址:https://github.com/Leavingseason/xDeepFM
xDeepFM中也是采用DNN的方式建模高阶特征交叉,大多数模型都是以bit-wise的方式建模特征交叉,这篇paper提出了一个基于NN模型,以显式,vector-wise的方式来学习特征交叉。xDeepFM可以看做是DCN和deepFM的联合变种。
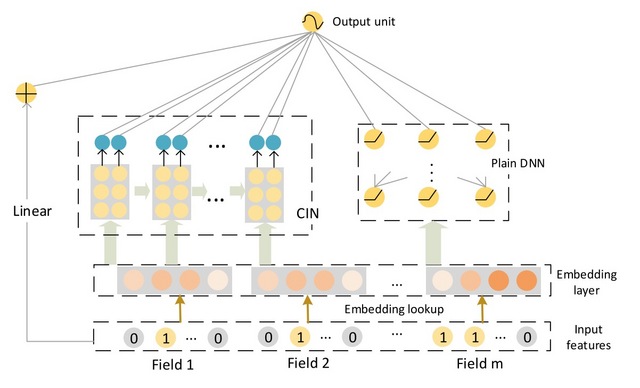
提出CIN(Compressed Interaction Network),在vector-wise级别上进行特征交叉,网络的复杂度不会随着交叉阶数进行指数增长。CIN的结构和RNN的结构非常相似,下一个hidden layer的output取决于最近的hidden layer和一个额外的input。我们在所有的layer上都维持有embedding vectors的结构,这样可以在vector-wise上做交叉。的计算方式是hidden layer 和原始特征 外积(沿着每个embedding的维度)获得, 定义一个filter W, 最后获得。
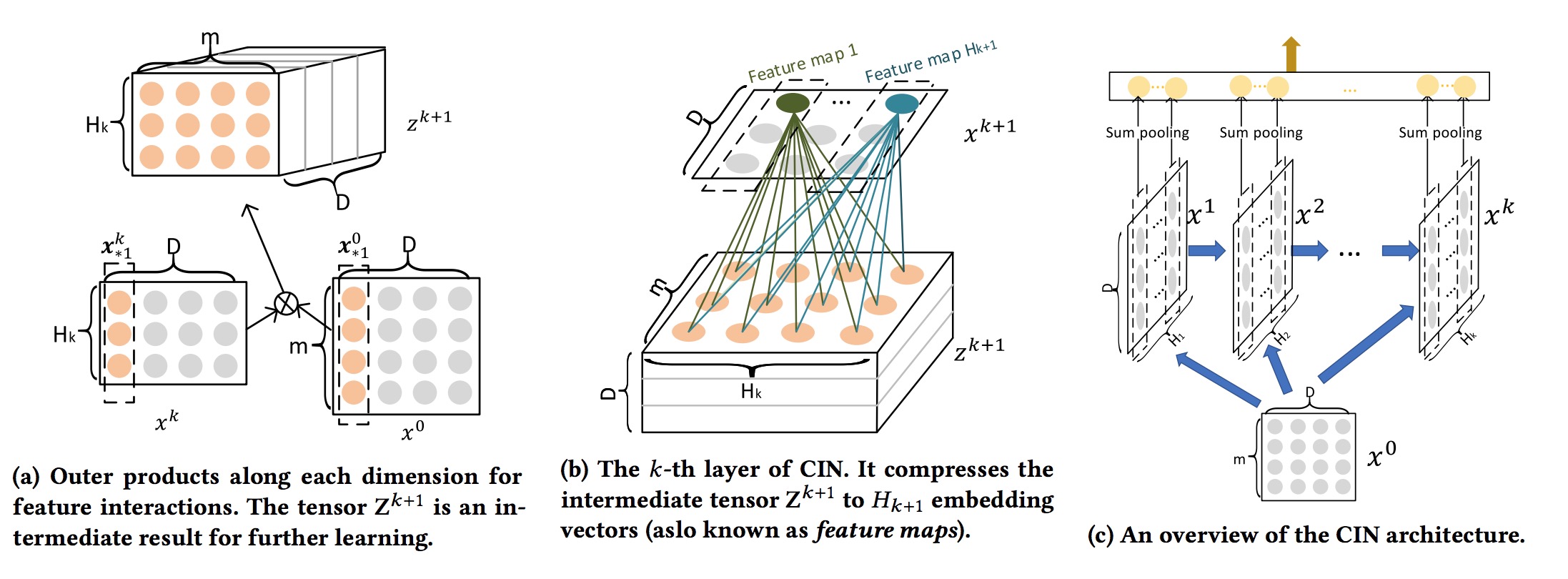
最后得到一个pooling vector 和linear 层以及deep层连接使用。